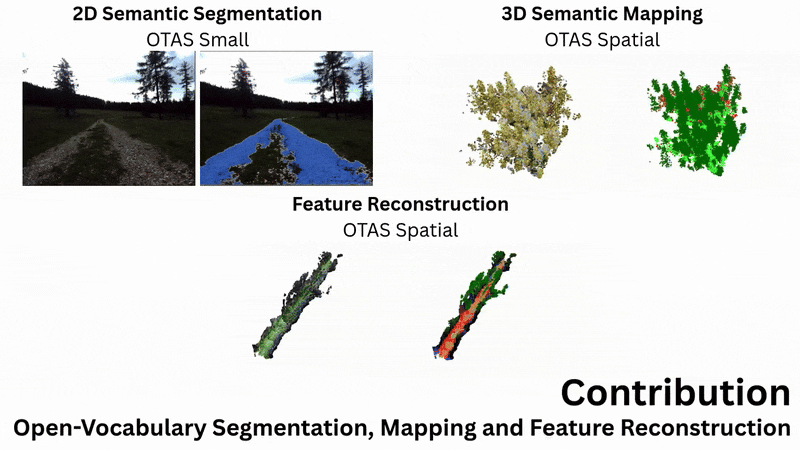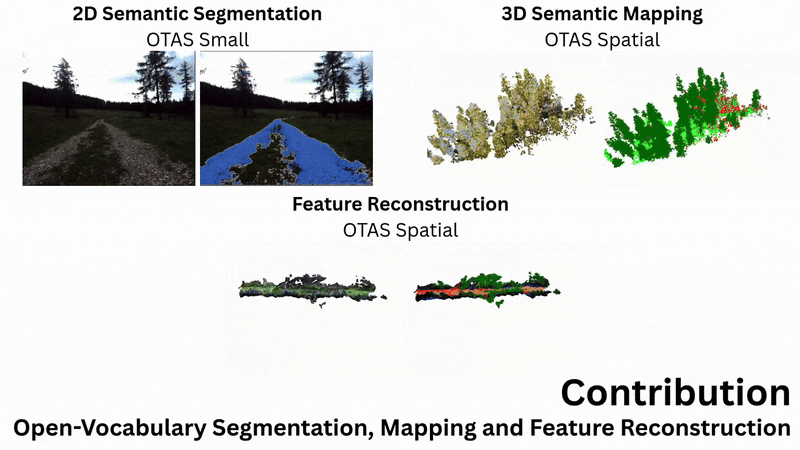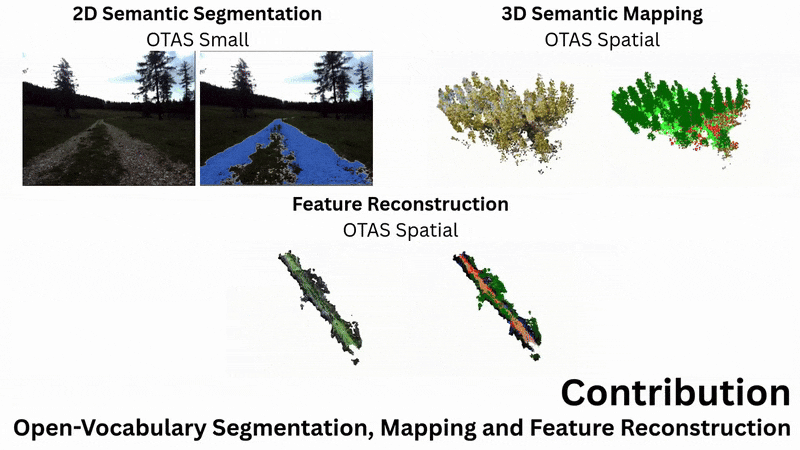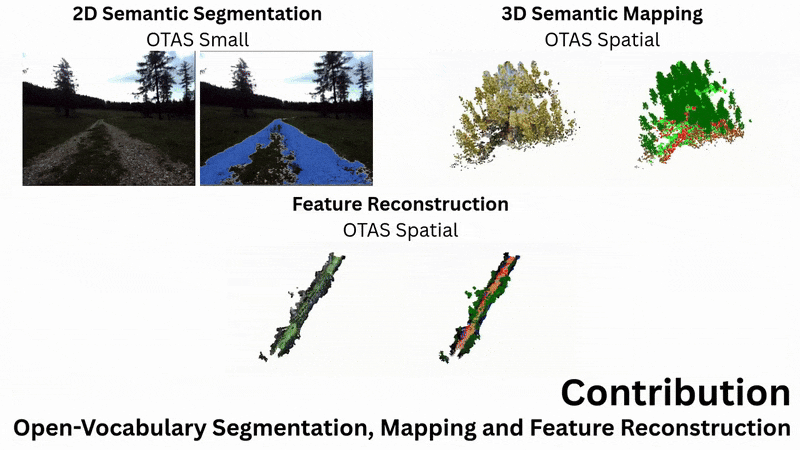
Abstract
Understanding open-world semantics is critical for robotic planning and control, particularly in unstructured outdoor environments.
Existing vision-language mapping approaches typically rely on object-centric segmentation priors, which often fail outdoors due to semantic ambiguities and indistinct class boundaries.
We propose OTAS—an Open-vocabulary Token Alignment method for outdoor Segmentation.
OTAS addresses the limitations of open-vocabulary segmentation models by extracting semantic structure directly from the output tokens of pre-trained vision models.
By clustering semantically similar structures across single and multiple views and grounding them in language, OTAS reconstructs a geometrically consistent feature field that supports open-vocabulary segmentation queries.
Our method operates in a zero-shot manner, without scene-specific fine-tuning, and achieves real-time performance of up to ~17 fps.
On the Off-Road Freespace Detection dataset, OTAS yields a modest IoU improvement over fine-tuned and open-vocabulary 2D segmentation baselines.
In 3D segmentation on TartanAir, it achieves up to a 151% relative IoU improvement compared to existing open-vocabulary mapping methods.
Real-world reconstructions further demonstrate OTAS' applicability to robotic deployment. Code and a ROS node are available on GitHub.
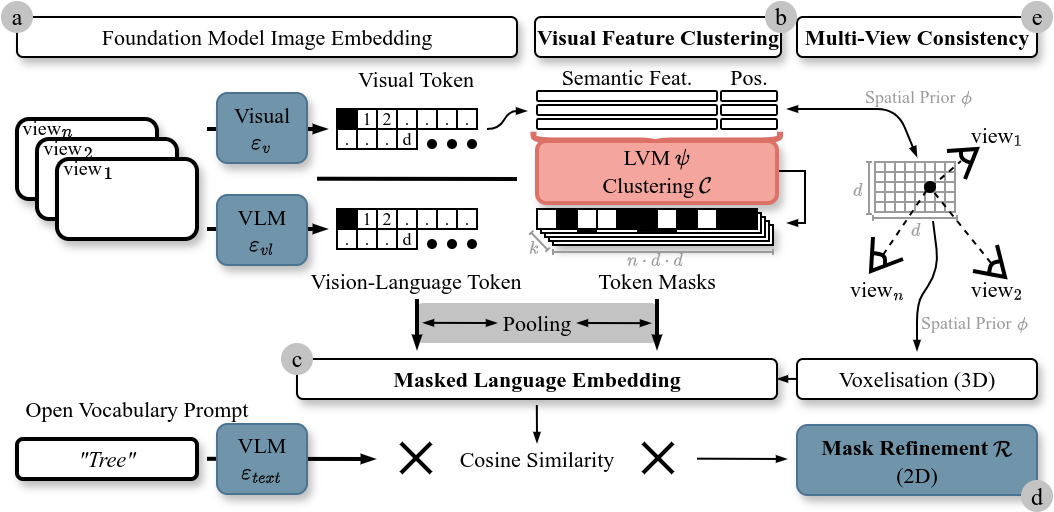
Method Overview
OTAS introduces a training-free token alignment that fuses self-supervised visual tokens with language embeddings,
regularising VLM features and improving non-object-class segmentation, without per-scene tuning.
It enables robust feature regularisation for non-object-centric outdoor environments.
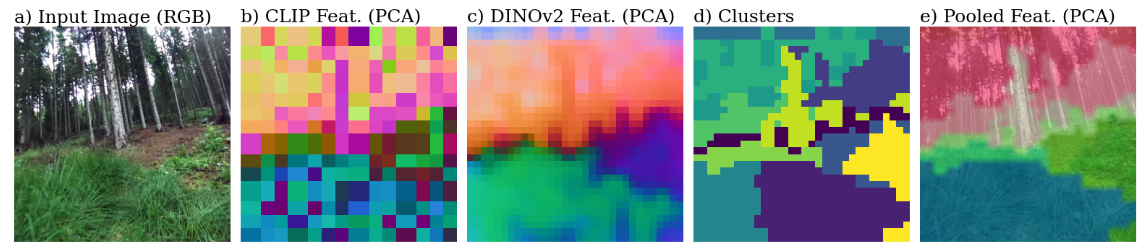
OTAS aligns encoder output tokens through self-supervised clustering and lightweight pooling steps:
- a) OTAS encodes input views using frozen encoders.
- b) Patch tokens of the visual encoder are reduced and clustered to obtain semantic masks.
- c) Masks are pooled with vision-language patch tokens for natural language grounding.
- d) A frozen mask refinement network optionally projects semantic similarity to prompts to pixel-level (2D).
- e) Clustering and pooling are optionally conditioned on environment geometry through projection (3D).
Quantitative Zero-Shot Segmentation Results (IoU)
Multi-View (3D) - TartanAir (selected scenes)
| Method | mIoU (%) |
|---|
| OpenFusion | 20.16 |
| ConceptGraphs | 29.85 |
| OTAS (Ours) | 49.56 |
Single-View (2D) - Offroad Freespace Detection Dataset
| Method | IoU (%) |
|---|
| SEEM | 51.31 |
| Grounded SAM | 90.49 |
| Grounded SAM-2 | 93.32 |
| OTAS Small (Ours) | 91.72 |
| OTAS Large (Ours) | 94.34 |
Real-World Experiments
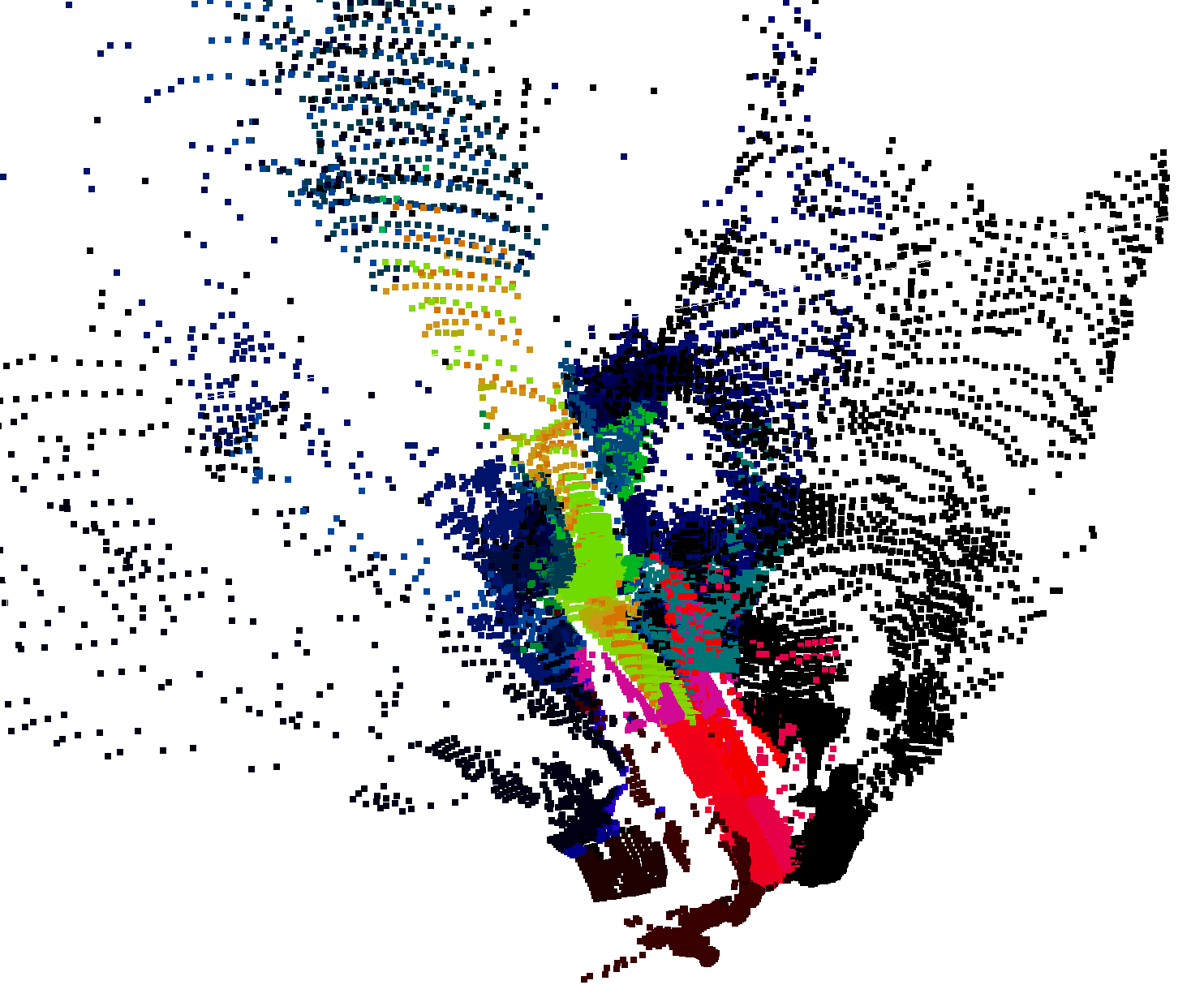
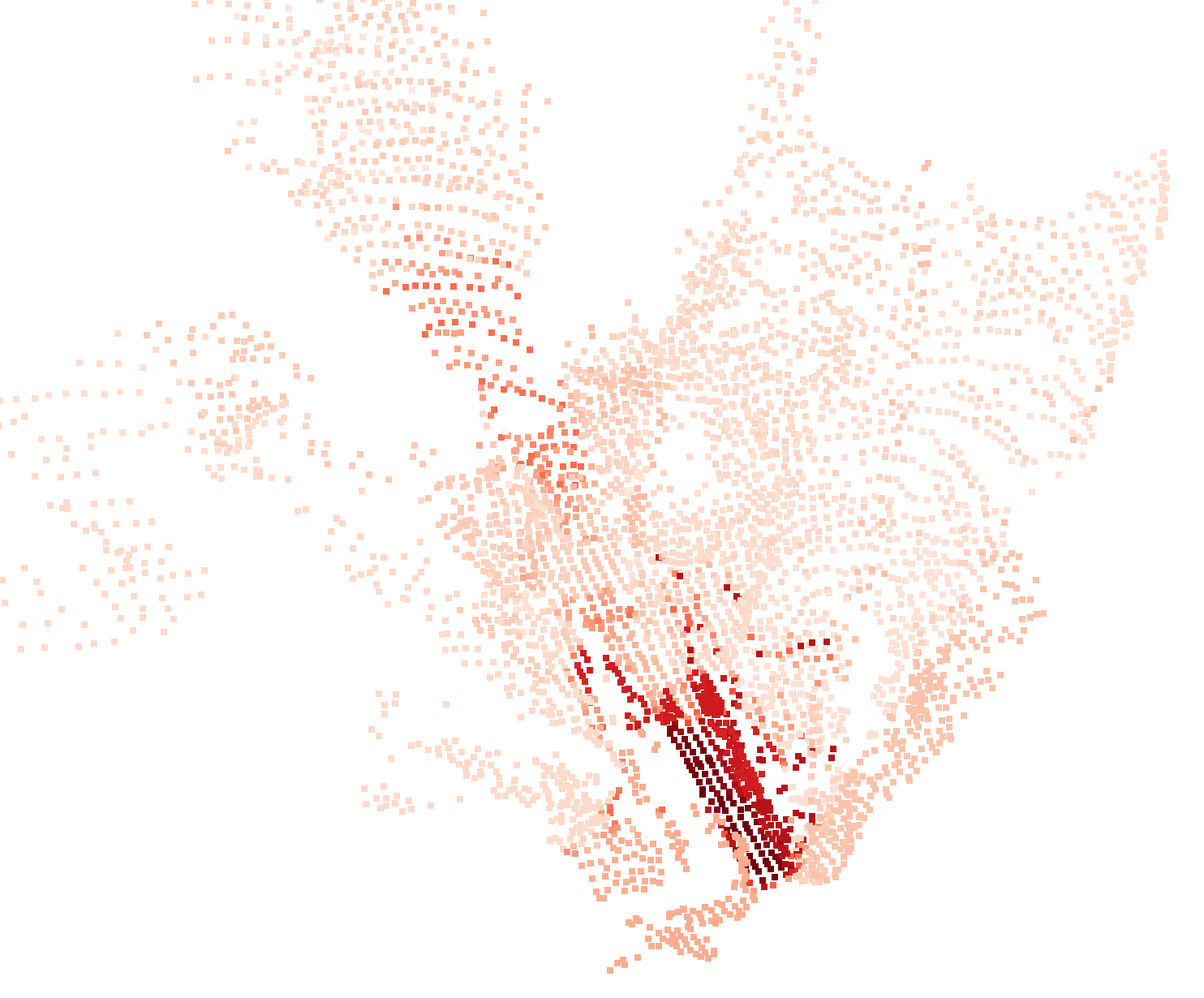
Real-world reconstructions on the
RoboNav Dataset
demonstrate OTAS' applicability to real robotics data.
From left to right: Example input image, geometric reconstruction, PCA over semantic reconstruction,
and open-language segmentation over the feature field.

Input Image (1 of n)
Geometric Reconstruction
PCA over Semantics
Open-Language Segmentation
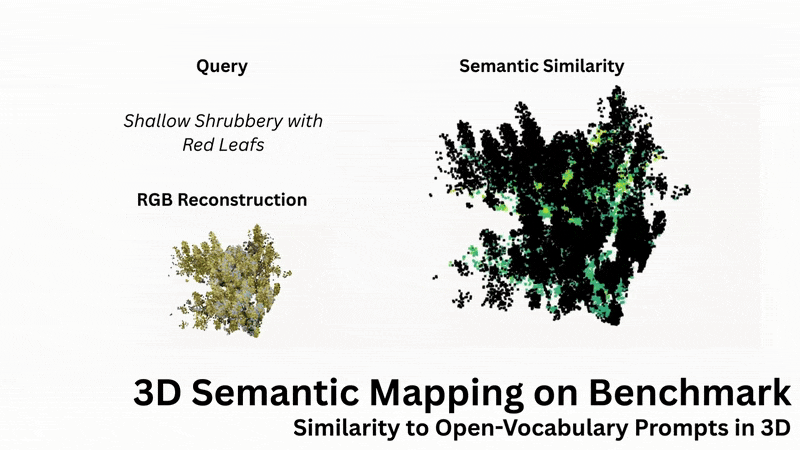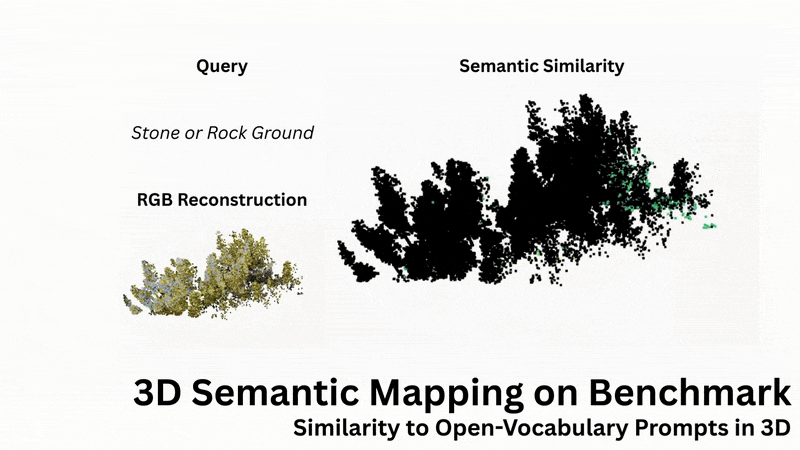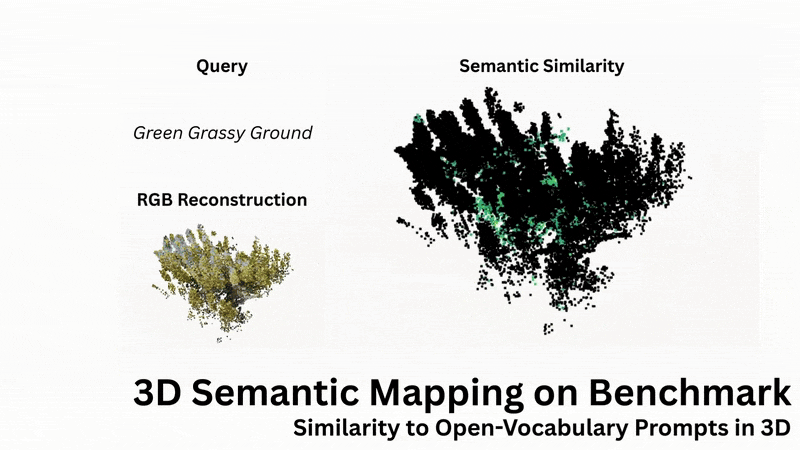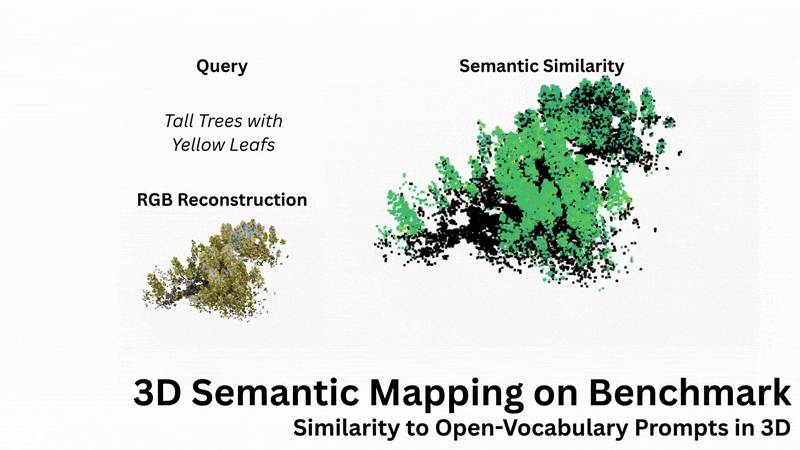
Open-Language Similarity Assessment
OTAS supports open-vocabulary similarity queries in 3D scenes, enabling retrieval and visualisation of semantic concepts such as terrain types. Contrary to existing methods, OTAS extracts dense language embeddings, even in cluttered and highly textured outdoor scenes.
How to use in your own projects
OTAS only requires python dependencies and pretrained encoder checkpoints. After installation with pip, inference can be performed with just a few lines of code.
We include an 11-line example for reconstruction from phone photos of a hiking trail in the Alps.
From left to right: Example input image, Geometric reconstruction, PCA over semantics, similarity to prompt "wooden bridge".
Check out our demo notebook and source code for more details.
BibTeX Citation
If you use this work, please cite:
@misc{Schwaiger2025OTAS,
title = {OTAS: Open-vocabulary Token Alignment for Outdoor Segmentation. arXiv preprint arXiv:2507.08851},
author = {Simon Schwaiger and Stefan Thalhammer and Wilfried Wöber and Gerald Steinbauer-Wagner},
year = {2025},
url = {https://arxiv.org/abs/2507.08851}
}